색인

표준오차란?
표준오차를 이해하기 위해서는 모집단과 표본의 평균, 분산, 표준분산에 대한 이해가 필요하다. 해당 카테고리에 내용을 정리하였으니 참고하시기 바랍니다.
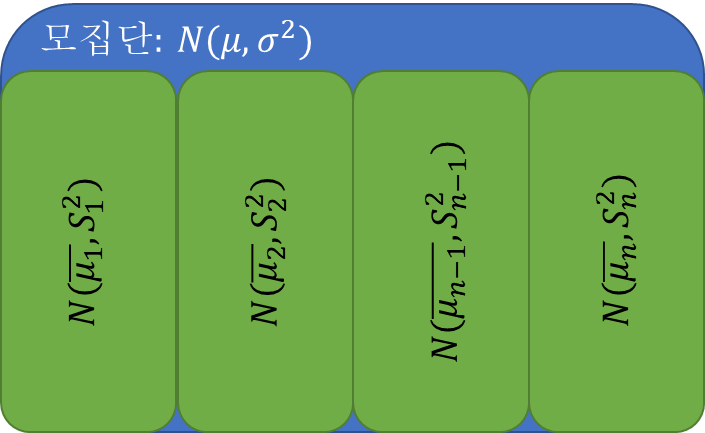
그림과 같이 모집단에서 중복 순열로 표본을 추출하면 각 표본의 평균을 구할 수 있습니다. 표본 평균 기호는 모집단 평균 기호에 막대 기호를 추가하여 표시됩니다.
여기서 모집단 평균은 샘플의 평균을 수집하고 다음과 같이 평균화하여 얻습니다.
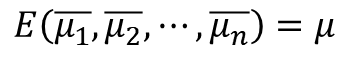
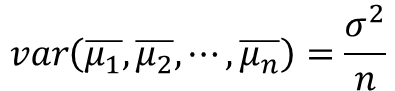
그리고 표본집단의 평균으로 발산을 구하면 수학식 2와 같이 모집단 분산을 n으로 나눈 값을 구하였다.
이전 포스터(https://scribblinganything.687)에서는 모집단 분산을 다음과 같이 결정했습니다.
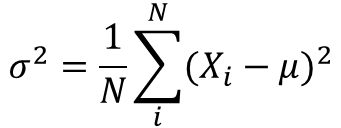
방정식 3은 평균과 모집단 데이터 Xi의 차이를 찾아 분산을 확인해야 합니다.
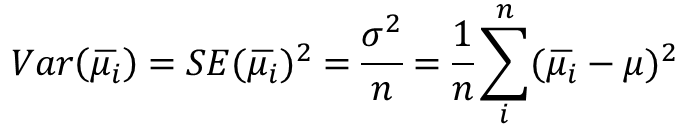
수학식 4는 분산을 계산하기 위해 수학식 2를 확장한 것이지만, ui는 표본마다 다르기 때문에 추정치이다. 다시 말해서, 추정치가 평균에서 얼마나 떨어져 있는지를 나타내는 지표특성상 오류 구성 요소를 확인합니다. 따라서 방정식 4는 표준 오차의 제곱으로 표현됩니다. 값의 제곱근을 취하면 표준 오차가 됩니다.
선형 회귀에서 표준 오차(SE)란 무엇입니까?
선형 회귀 공식은 다음과 같이 개발됩니다.
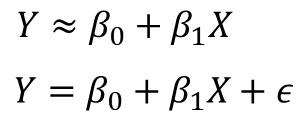
X, Y는 사용자가 이미 알고 있는 데이터 입력 및 출력 값입니다. 베타 값은 절편과 기울기 값입니다. 베타 값을 찾는 과정이 선형 회귀 모델링 과정입니다.
여기서 베타파라미터를 구하고 X와 Y의 데이터를 제곱으로 입력했을 때 발생하는 오차의 정도를 나타내는 Residual Sum of Squares(RSS) 개념이 들어온다.
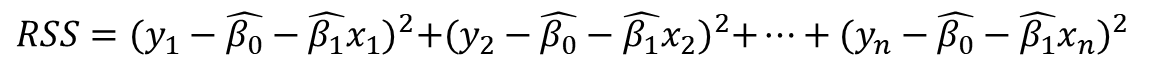
수학식 6은 실제값에서 추정값을 뺀 값을 제곱하여 오차성분의 크기를 구한 RSS 공식이다. 여기서 모자는 추정된 매개변수를 의미합니다.
여기서 수학식 6은 베타에 대한 2차 방정식, 즉 가장 낮은 점이 존재하는 그래프이기 때문에 볼록함수이다. 각 각도의 편도함수가 0이 되는 최소점은 다음과 같습니다.
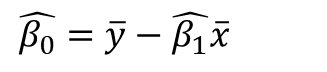
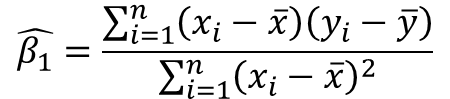
x 막대는 평균값을 의미합니다. 위의 방정식 1에서 4까지의 막대는 추정 ^ 표기법이어야 합니다. 혼란을 드려 죄송합니다.
방정식 5에서 X와 Y는 우리가 수집한 데이터이지만 결국에는 이 데이터를 모델을 구축하고 예측하는 데 사용할 것입니다. 즉, 표본 모집단을 의미합니다. 여기서 X, Y는 모집단의 일부 표본 값입니다. 따라서 베타 매개변수에 대한 SE는 방정식 4, 방정식 7 및 8을 사용하여 얻을 수 있습니다.
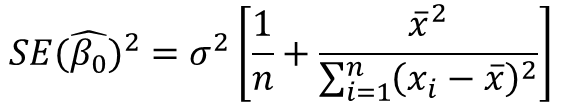
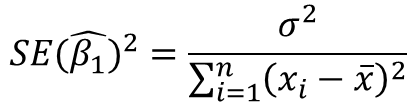
여기서 시그마 제곱 값은 수학식 5에서 모집단 오차로 인한 분산이므로 다음과 같이 표현할 수 있다.
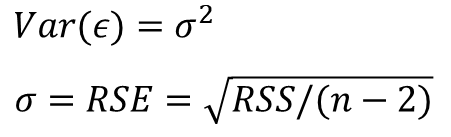
그리고 샘플에서 생성된 엡실론은 상관관계가 없는 속성을 가집니다. 그리고 시그마는 RSS 값을 n-2 곱하기 1/2로 나눈 값을 RSE(Residual Standard Error)라고 합니다. n-2를 나누는 이유는 RSS 공식에서 x와 y가 상관 관계가 있다고 생각하기 때문에 두 자유도가 누락되었습니다(그건 전적으로 제 생각입니다).
수학식 9에서 베타 0 절편은 입력 모집단 평균이 0일 때 표준 오차가 감소하는 특성입니다.모자 생각해 보면 입력 값이 0을 중심으로 고르게 분포되거나 밀집되어 있으면 오류없이 교차점의 값이 결정됩니다.
수학식 10에서 입력값 xi의 값이 퍼질수록 오차가 작아진다. 이 부분을 상식적으로 생각하면 선형 함수인 기울기 성분이 x의 값이 널리 퍼져 있을 때 더 적은 오차를 반영할 가능성이 높기 때문입니다.